几乎每个行业都在提议使用人工智能。材料科学的研发相对于这一趋势而言还相对较晚,并且存在许多针对特定行业的障碍,但是机遇已经开始被意识到并且潜在的影响是巨大的。
材料信息学是将以数据为中心的方法用于材料科学的发现和发展。改进的数据基础架构和机器学习解决方案可实现这一目标;这将是研究人员进行研发项目的方式的范式转变,有关为什么现在采用这种方法的讨论可以在上一篇文章中看到。在最初商业应用的关键时刻,IDTechEx发布了有关“ 2020-2030年材料信息学”这一主题的最全面的技术市场报告。
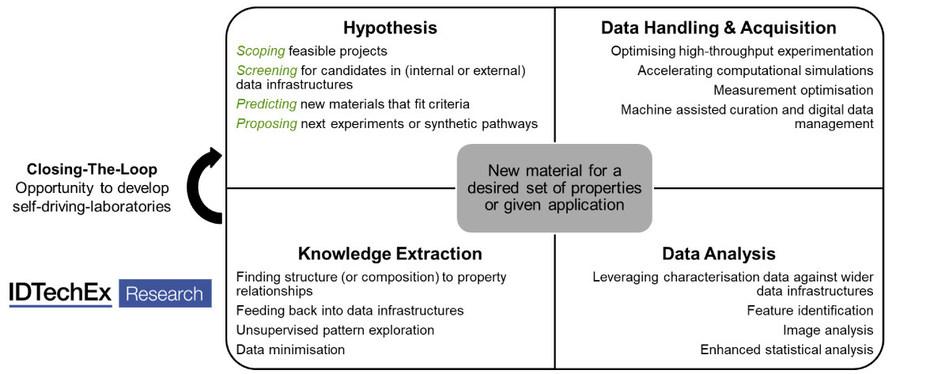
物质信息学可以在实验过程的每个阶段使用,如下图所示。有多种潜在优势,包括识别新物种或新关系,从现有数据中提取价值以及在现有化合物上生成用例IP,但是在大多数情况下,这都是有关加快上市时间和提供竞争优势的。
量化加速上市的时间很困难,但对于外部公司展示和证明任何投资是必不可少的。许多人要求使用大量示例,将数百万个候选者和/或数千个实验减少为更易于管理的数百个甚至数十个解决方案或迭代。
IDTechEx将报告中进行的项目分为6个主要类别。先前的文章已经展示了如何在多个应用程序中使用它。
一个关键概念是“逆向设计”的思想。简而言之,这可能涉及训练一个模型,该模型允许输入特性并提出配方,组成,工艺参数或更多。这些属性并不仅是物理性质,还可以是成本,毒性,地理可用性或更多。该技术适用于设计材料或使用材料进行设计的任何人,目的是使这种逆向设计与初始产品设计完全集成。Citrine信息学与西门子之间的合作已最有效地证明了这一点。据说,他们希望设计师将材料视为他们的“自由度”之一,并允许材料公司成为“合作伙伴而不是供应商”。
为清楚起见,请勿将材料信息学与计算仿真(例如DFT计算)相混淆。在过去的几十年中,这种材料建模取得了重大进展(由BIOVIA和Schrödinger等人领导),并且随着计算能力的不断提高,这种增长只会增加。JSR Corporation和QSimulate之间的公告是对此的近期著名证据。可以按照与任何物理实验输入数据相同的方式使用数据。实际上,使用MI的一种通用方法可以减少昂贵且费时的仿真数量,简化这些研究项目并绘制新颖的关系。
主要问题是材料数据集的局限性。这与识别自动驾驶汽车或复杂的互联网搜索引擎中的物体不同,材料科学带来了许多特定的问题。数据通常是稀疏的,高维的,有偏见的和嘈杂的,这意味着理解建议的输出中的不确定性至关重要。考虑到群集的复杂数据,将项目投影到“未知”非常具有挑战性。
处理小型数据集的方法很多,其中可能涉及通过高通量实验生成一个数据集,利用外部数据存储库以及最重要的是集成领域知识。
生成和利用数据存储库是材料信息学的核心主题。有很多非常定制的或更通用的存储库,它们收集已发布的结构,属性和其他数据。这些由公共或私人组织运营,尽管可能有局限性(例如对数据的不确定性以及仅具有“阳性”已发布的结果有偏见),但它们可以作为培训模型或筛选候选人的无与伦比的资源。更不用说大型数据集为利用更复杂的深度学习方法提供了机会。